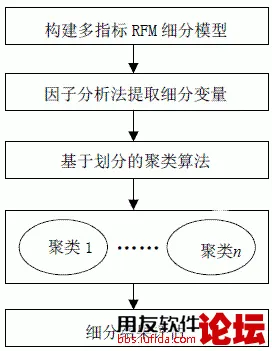
在互联网大战中,我们可以看到,不管是否能够实现盈利,商家首先要做的就是抢占流量,而这些流量正是客户群。不仅互联网,线下商业同样如此,“客户”是销售的来源,如何能够吸引客户、留住客户,并使其重复消费?需要根据不同客户类型提供不同的产品和服务内容。对客户消费数据的挖掘起到重要引导作用。 据美国数据库营销研究所Arthur Hughes提出“RFM模型”,认为它构成了数据分析最好的指标,是衡量客户价值和客户创利能力的重要工具和手段。在RFM模式中,R(Recency)表示客户购买的时间有多远,F(Frequency)表示客户在时间内购买的次数,M (Monetary)表示客户在时间内购买的金额。一般的分析型CRM着重在对于客户贡献度的分析,RFM则强调以客户的行为来区分客户。 用友集团UAP中心大数据专家曾小青表示,在企业,海量数据分析一直是技术瓶颈,基于数据挖掘技术对客户进行细分,既是传统客户细分方法的补充, 也是商业分析技术的重要应用。曾小青曾经在商业分析系统业务模型、高性能实时数据挖掘方面取得了一定研究成果。同时,他看到了传统的RFM模型仍存在不足,因此提出了一套经过改进的针对消费数据挖掘的多指标RFM客户细分方案。曾小青介绍,这个方案包含了3种类型10各指标的RFM细分模型。并通过因子分析法从中提取细分变量,再使用基于划分的聚类算法进行客户细分。 具体流程可细分为以下4 个步骤:(1)构建多指标RFM 细分模型;(2)使用因子分析法提取细分变量。因子分析得出潜在因子个数和因子解释信息的能力,计算每个客户在因子上的得分;(3)将客户在因子上的得分作为基于划分的聚类方法的输入数据,进行聚类;(4)评估客户细分结果。
研究方法 首先,构建多指标RFM模型。曾小青认为,客户的消费行为是一个很复杂的过程,“R、F、M”三个指标,从一定程度上反映了客户购买和客户价值,但仍存在一些缺陷。对于R表示的最近购买,新客户和老客户的表现可能相同,即在观察时间段内同时具有最近购买的记录,然而企业却无法根据R来判断客户的新老属性,并针对拥有不同属性的客户提供不同的决策,最终导致决策的偏颇。F表示的消费频度在较短的周期内(如月)能说明客户的购买强度,但是当一个客户的周期较长(如一年),那么F作为在这个较长周期内的购买次数将无法说明客户的购买规律,如客户在哪个月的购买最为频繁,在哪个月购买最为薄弱,哪几个月低于了平均购买?同理客户的消费金额也是一样。传统RFM模型无法反映这些信息,然而这些信息又能为企业营销策略提供正确的指导。 为避免这些缺陷,曾小青将传统RFM进行改进,产生了多指标RFM模型。在深入分析传统RFM指标的基础上,构建包含3种类型10个指标的RFM细分模型,用以较为全面的反映客户价值。
曾小青介绍,用多指标代替传统的消费近度、频度和值度,主要基于以下考虑:第一,用多个购买时间代替单一的最近购买,可真实反映客户在时间上的购买规律和整体的购买时间跨度,更易于区分新老客户;第二,用多个频率数据代替整体的消费频度,能更好的体现出购买的集中性,知道客户最最频繁购买月份、最弱购买月份和相关金额,从而为市场营销提供依据;第三,通过平均金额可分析出用户的平均消费额度。结合总体消费金额,可以容易判断出大份额顾客。 其次,利用因子分析法提取细分变量。传统RFM模型三个指标在权重划分问题上存在着各种不同的意见。Hughes认为RFM在衡量一个问题上的权重是一致的,因而并没有给予不同的划分。而Stone通过对信用卡实证分析,认为各个指标的权重并不相同,应该给予频度最高,近度次之,值度最低的权重。国内普遍采用的权重分析方法为层次分析法,但是层次分析方法相比权重的确定更倾向于方案决策的制定,而且在构造初始特征矩阵时,由于人为因素的影响较大,最终导致了权重结果的不准确。在考虑多指标RFM模型指标权重时,曾小青选用因子分析法,找出潜在影响客户细分的因素,确定因子个数和客户在因子上的得分,根据各因子解释客户细分的程度确定各因子的权重。 因子分析(factor analysis)是一种数据简化的技术。它通过研究众多变量之间的内部依赖关系,探求观测数据中的基本结构,并用少数几个假想变量来表示其基本的数据结构。假想变量(即因子)能够反映原来众多变量的主要信息。根据因子分析的一般步骤,可将改进RFM模型在各因子上的得分定义为:
其中, X为改进RFM模型指标,FACTOR为因子,矩阵为因子得分系数矩阵。 第三,基于划分的客户细分聚类算法。“在选择聚类的算法时,由于改进的RFM指标都是数值型数据,不是分类属性数据,并希望客户类型互不重叠,因此我们使用基于划分的聚类算法(Partitioning Methods)进行客户细分。”曾小青解释道。它以各个指标在因子上的得分作为判断依据,将相似性较强的客户细分在一个类别中,相似性较弱的客户存在与不同类别中,确保了同一类别中的距离最小。最常用的基于划分的启发式聚类算法是k-means算法和k-中心点算法。k-means算法简单快速,但容易受噪声点和孤立点影响,且不适用于发现非凸面形状的聚类。k-中心点不是用质心来代表聚类,而是用最靠近中心的一个数据对象来代表聚类,消除了对孤立点的敏感性,具有较强的鲁棒行,但执行代价更高。典型的k-中心点算法有PAM算法、CLARA算法等。为了处理大数据集,可采用CLARA方法进行聚类,通过改进启发式函数,或结合其它方法,比如粗糙集法、遗传算法、Tabu算法等可进一步提升聚类效果。 经过改进的多指标RFM客户细分法,,避免了人为因素带来的数据偏差,提高了对客户细分的科学性和准确性。为数据挖掘的应用,以及消费行为的研究都提供了更好的依据。 |
 |站长微信|Archiver|手机版|小黑屋|用友之家
( 蜀ICP备07505338号|
|站长微信|Archiver|手机版|小黑屋|用友之家
( 蜀ICP备07505338号|![]() 51072502110008 )
51072502110008 )
GMT+8, 2024-5-17 04:28 , Processed in 0.026989 second(s), 10 queries , Gzip On, Redis On.
Powered by Discuz! X3.5
© 2001-2024 Discuz! Team.